Lean Search Design with Spinque Desk
Posted on 27/02/2018 by Laurens Vreekamp
Suppose you receive the following assignment from an editor-in-chief of a national newspaper:
"Every day I want to see which news topics we did not cover yesterday (and our competition did)."
How would you handle this?
I had this search query in mind for quite a while and now that I work at Spinque, I wanted to know how Spinque Desk could help me solve it.
Journalistic background
You can probably imagine that any editor-in-chief of a news medium wants to know as much as possible - including what she doesn't know. And in the case of the specific assignment at the top of this page you probably want to know what you did not do compared to other news media. (You missed the scoop on Halbe Zijlstra's lie - okay, you already knew that, but really: there are things you don't know you missed.)
The screenshot below shows a fictional dashboard for an editor-in-chief. The top left part is the 'overview of missed topics':
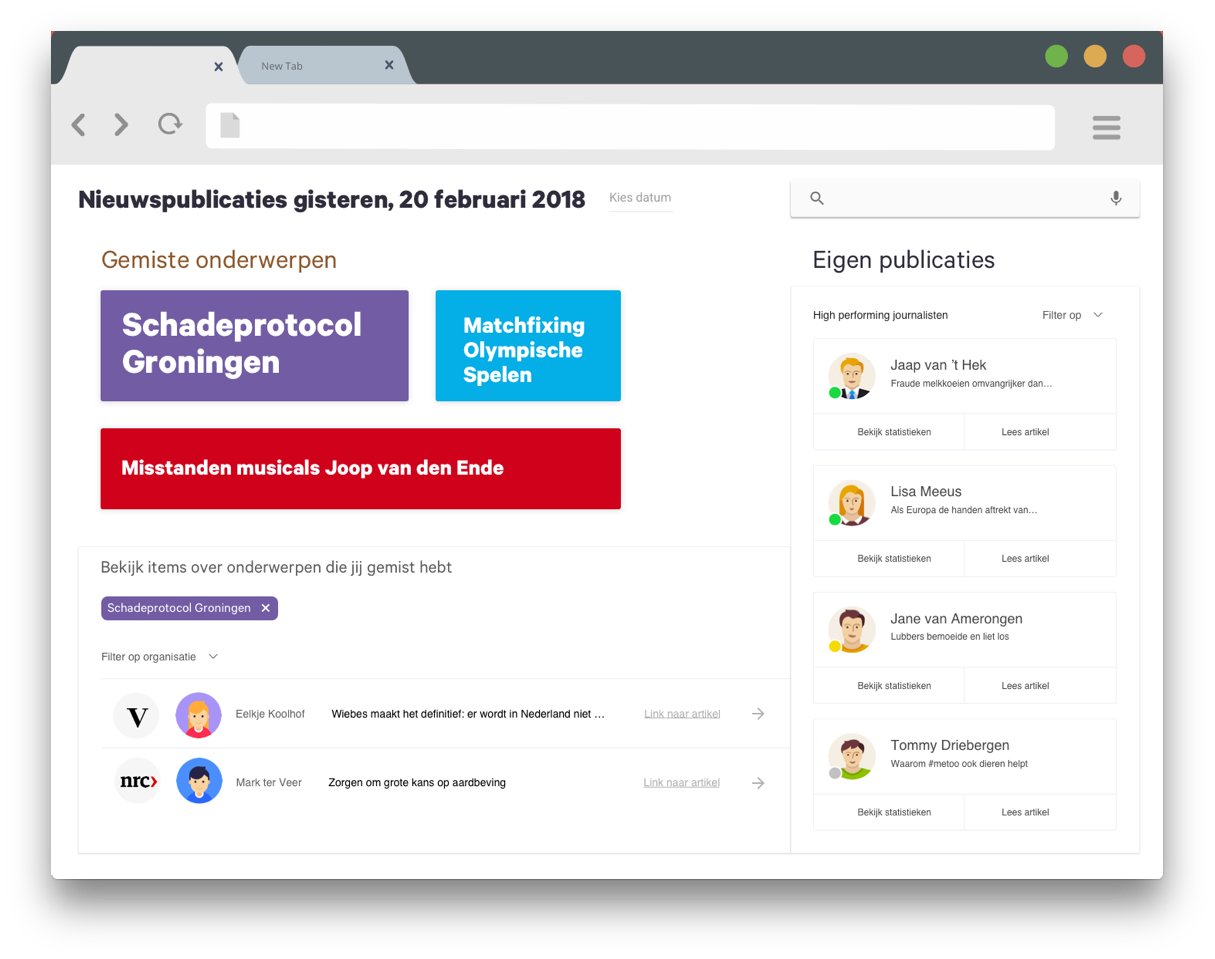
Why you would want an overview like this every day? To check the uniqueness of the editorial course you've set. To see if your editors didn't miss any important issues. And to be aware of what 'the others' are doing.
And while we're at it: you may also want to know the opposite. Also over longer or specific periods time. And not unimportant either: does the focus of your own publications correspond with the subjects and approach in which you are (or want to be) a leader?
Oh yes, you would also like to link this information to your web analytics. So that you can answer the following three questions:
- Do we make what we want to make (editorial objectives)?
- Do we thereby reach our intended audience (targets)?
- Does our audience value our productions (conversion)?
Required ingredients
And then you realise: formulating the assignment and asking the questions is relatively simple, but... who is going to answer these questions? And what do you need for that?
Let me help you by indicating what I have learned about this recently. You need at least the following:
- Data & content:
- a dataset of competitor content, updated daily,
- your own dataset with published content
- Web analytics
- An information specialist
- A number of developers who build and connect all solutions.
- Consensus regarding:
- what is considered 'relevant' within the organization,
- what is considered to be 'unique',
- what does and does not belong to the editorial course,
- when something is satisfactorily covered,
- which characteristics demonstrate leadership
Lean search design versus waterfall method
With Spinque Desk at hand, I actually didn't need more than a dataset with news articles (which I "coincidentally" still had) to get started. As an information specialist in the field of Dutch journalism, I naturally had an idea about relevant results. When the first version of my self-designed search engine returned its first articles however, I noticed that I had to think a little more about what should really be on the dashboard.
Traditionally, such a development process would look like this: someone has a question and gives an assignment, it is discussed, they go to the drawing board, a briefing is drawn up, a developer is sought, de-briefs and new proposals are made, and then, finally, development can start... only to find out that the original question was actually not the right one. Call it the waterfall method of search engine design.
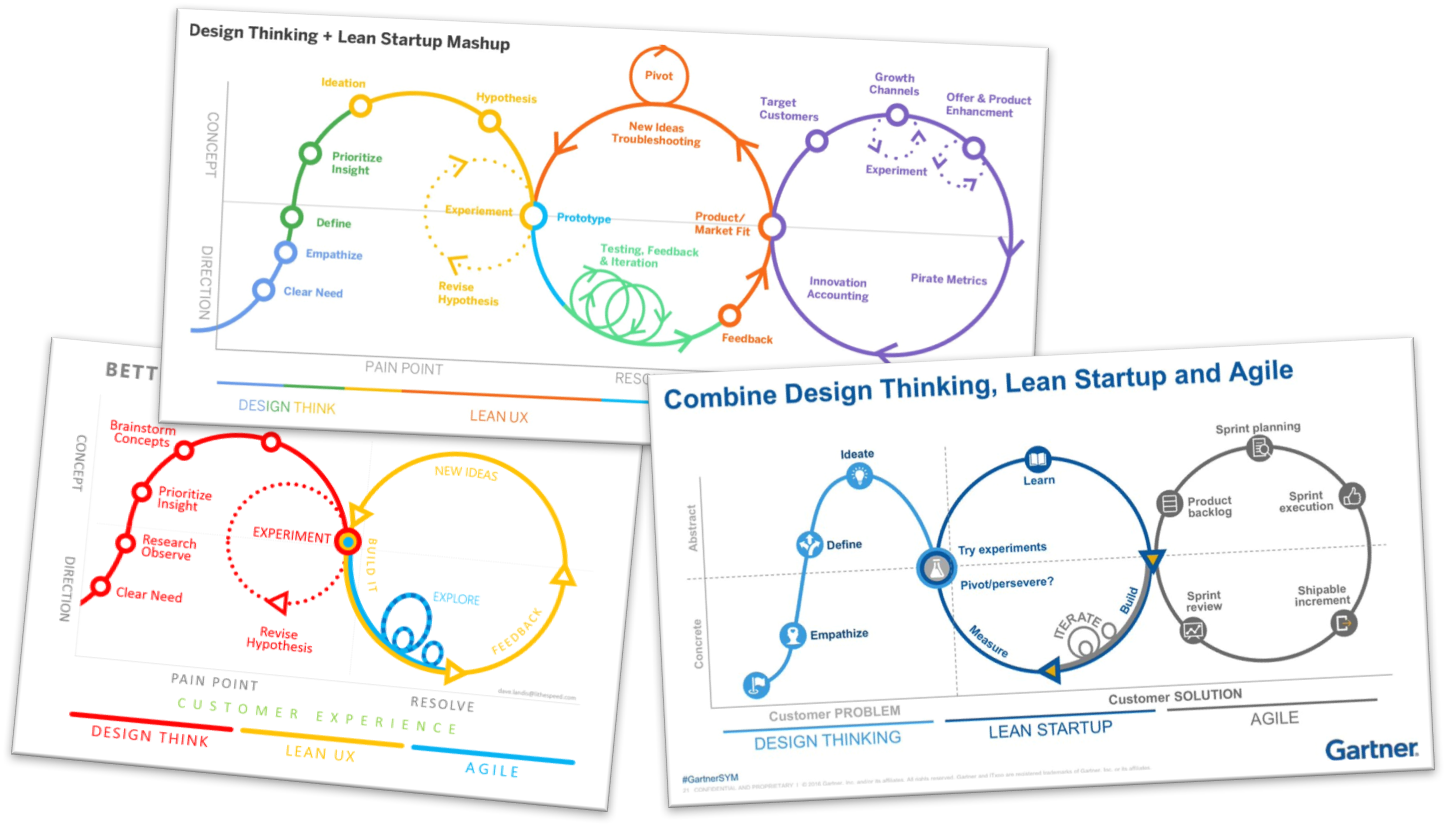
With the lean method, which fits well with Spinque Desk, you have immediate results! All you need is a question/assignment (a good idea!), a dataset and access to Spinque Desk.
Strategy 1.0
My approach to the initial question was as follows - call it my three-step pseudo-strategy:
- Select all articles published on a specific date. Get all articles that appeared in all national newspapers yesterday.
- Show the most important words and phrases used. Filter the most frequently used words and word combinations from all those articles (of course with the exception of frequently used words such as 'the-a-because-since-with' -etc).
- Compare 'their' glossary to 'ours'. Compare those filtered results with the words from our own published articles, and list which words we didn't use.
On the dashboard I would then like to show the corresponding articles, as indicated in Figure 1 - the dashboard sketch:
What turned out not to work well with this approach is that you do not get articles back but words. And those words did not always turn out to represent important topics, let alone real 'news items' or sketch the core of an article. In short, this strategy failed to answer the question.
Strategy 2.0
After consulting my colleagues at Spinque, I took a different approach with this new insight: my search is initially not about topics but about the relevance of articles. My second pseudo strategy therefore went like this:
- Select all articles published on a specific date. Same step as with strategy version 1.0.
- Determine relevance. See what most editorial boards wrote about (both the competition and you). We do this by comparing the content of the articles. The notion of relevance is therefore the degree of popularity of the subject among different editorial boards.
- Show me the 'have nots'. See which articles from step 2 remain after removing the articles we did write about.
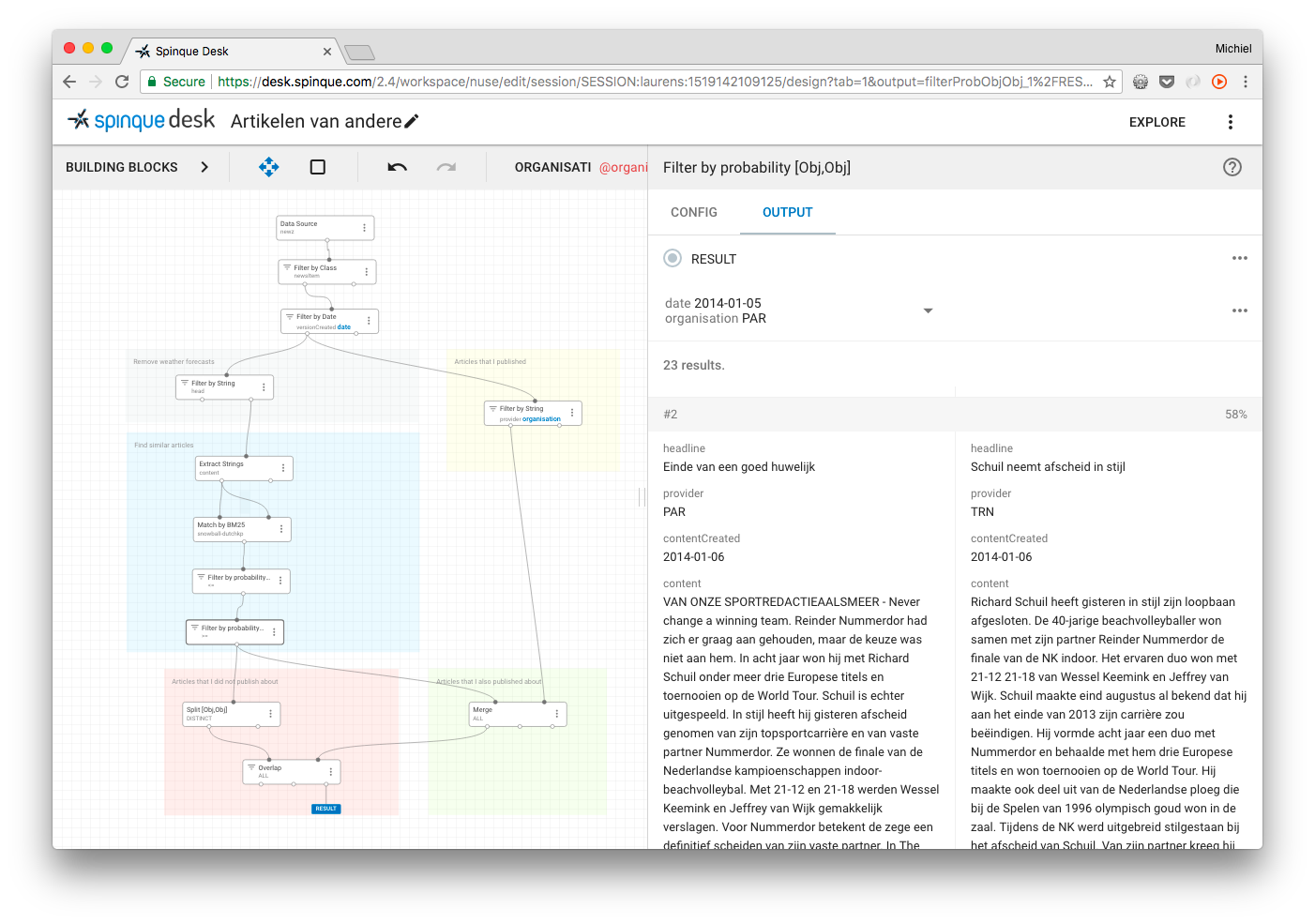
The screenshot above shows Spinque Desk. On the left you can see how the search strategy is made up of blocks. The blue area corresponds to step 2 of our pseudo-strategy: determine relevance. In that area you see the building blocks that determine to what extent the content of the articles should correspond.
On the right you can see an example of the intermediate result. An article by Het Parool (PAR) about the volleyball player Richard Schuil next to a similar article from Trouw (TRN). The final result contains the most relevant articles that the own editorial team has not written about (step 3 from the pseudo-strategy). This is achieved by the last blocks, bottom left.
Results
I came a long way with this strategy. Step 2 - determine relevance - I do not consider to be a search or design problem. This is really substantive in nature: what do we as searchers / inquirers find relevant (results)? If you have not yet determined this (and this is relatively often the case), you will find it -Spinque Desk at hand- with experiment and discussion easily and quickly. And, cheaper than if you would have hired a developer.
Ultimately, after strategy version 2.0, there are of course still some (small) wishes to improve the solution:
- the great influence of articles in local and regional publications on results
- the excessive influence that publications of a more specialist nature can have, such as the 'Financieele Dagblad', which mainly looks at news from a financial-economic perspective and also mainly publishes on that type of subject.
What I mainly learned is that with Spinque Desk you have a tool that allows you to start designing and testing your search engine almost immediately. Without having to think, draw, discuss and brief/debrief first, with a large team. By experimenting with strategies and being able to continuously evaluate a working search engine, you (quickly) discover what works and what does not work to get relevant results.
And most importantly: the lean search engine design process helps to immediately find out what is the question behind the question:
"What is the real (search) problem we want to solve?"
I'm curious what the next question from the editor-in-chief will be...