This research is funded by...
Posted on 20/04/2021 by Daria Alexander
At Spinque we do not only develop and implement search technology, we also do research. I started working at Spinque as a researcher in September 2020. Spinque takes part in the DoSSIER project, which aims to elucidate, model and address the different information needs of professional users. The project is international and is run in several countries such as the Netherlands, Italy, Austria, the UK and Greece. 15 PhD students take part in the project, and I am one of them. DoSSIER is funded under the Marie Skłodowska-Curie grant agreement. The project is divided into three domains: legal, medical and innovation. Spinque is one of the participants in the innovation domain. The project organises activities for PhD students despite the current corona situation, such as worksops. The workshops are held online, and their content varies: from information retrieval techniques to research ethics. PhD students also take initiatives, for instance, we created a 'reading club' where we discuss the articles that are important for the domain of information retrieval for professional search.
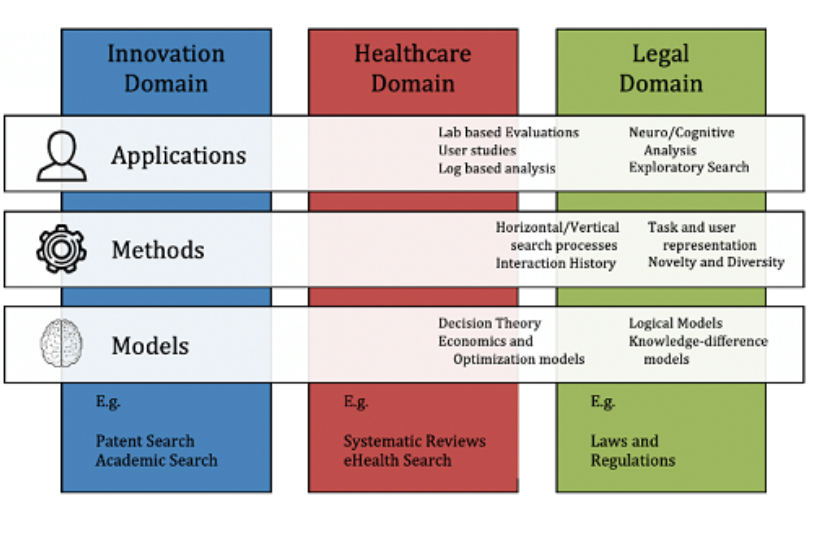
What is the role of Spinque in the project? Spinque is offering its unique search technology to create useful solutions to professional users. Spinque can use its technology to promote user-centered approaches in the domain of information retrieval and boost research that is focused on users' needs: such as needs of universities, historical archives, municipalities etc.
Since then, one of my main tasks was to develop a program that recognizes named entities in academic papers of a Dutch university, more specifically, funding information. Why funding information? It is important strategic information in academia. It is essential to know which research output is linked to which research program and what subsidies fund this type of research. How is this linked to knowledge graphs? Extracted named entities are added to a knowledge graph and drastically improve the quality of search for funding information.
AckNer
The program proceeds as follows:
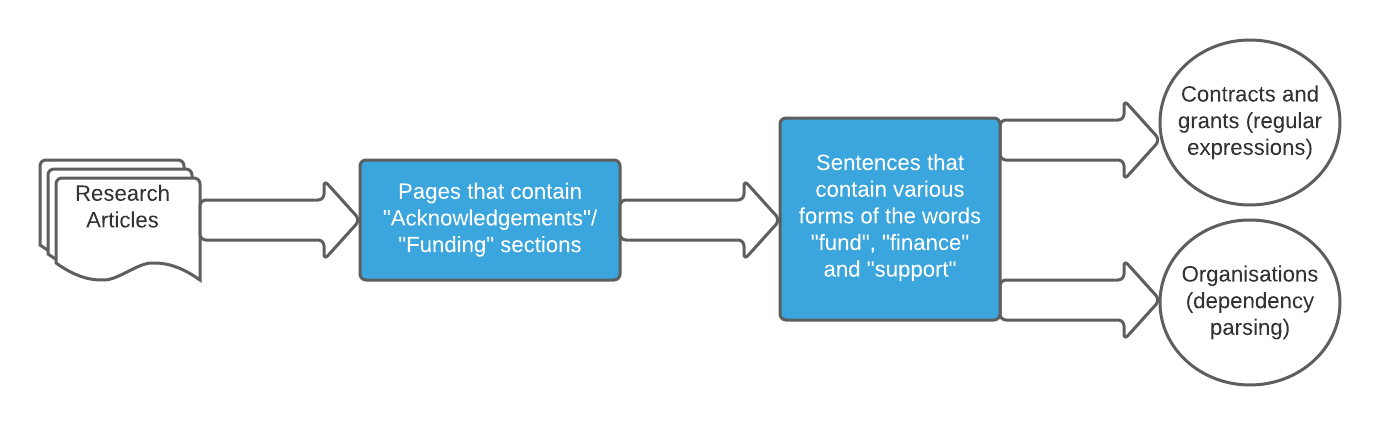
Funding information is usually contained in the 'Funding' and 'Acknowledgements' sections of the scientific papers, so the extraction of the pages that contain those parts is performed. Then we extract the sentences which have different forms of the words 'fund', 'finance' and 'support' in them. As the 'Acknowledgements' sections' language is standardised, those sentences usually begin with "This project is funded by...", "this research is supported by...". Due to the standardisation of the language, we can use the structure of the sentence to extract the necessary named entities, which will usually be in the middle and at the end of the sentences. For that we use parsing trees. We also extract the numbers of contracts and grants using regular expressions. The program is performing well on the sample of 321 articles and reaches a precision of 0.77 and a recall of 0.84. The F1 measure is 0.80. A high recall is the most important measure for us, as it shows that the program can extract as many named entities as possible, so we can put these entities in a knowledge graph.

BIR-2021
The paper about AckNer "This research is funded by... - Named Entity Recognition of financial information in research papers" was accepted for the BIR 2021 Workshop on Bibliometric-enhanced Information Retrieval that was held on the 1st of April 2021. This workshop explores issues related to academic search, at the intersection between Information Retrieval and Bibliometrics. I did a short presentation of the paper and was asked questions about the future use of the program for building knowledge graphs. Also, I had insights about the ways to use machine learning and deep learning for the program, such as to build a large set of training data that I can train the program on. After the workshop the paper was published in BIR-2021 proceedings. If you want to know more about AckNer, here is the link to the paper.
What's next?
The next step is to run AckNer on a larger dataset. We already ran AckNer on 7500 research papers and found some minor problems that are partially solved. Then we will run the program on a dataset that contains 40 - 50 thousand papers. By running AckNer on a large dataset we will build a knowledge repository from which the entities will be extracted via Spinque Desk and put in a knowledge graph. Their meaning will be disambiguated and unique identifiers will be assigned to them. The research in this field will be continued and other knowledge repositories will be created for using them in Spinque Desk and creating more knowledge graphs to help our clients to improve their search engines.